Alignment Step 1: Downsampling
Alignment of downsmapled subslices
[1]:
from scipy.spatial import distance
from pathlib import Path
from tqdm import tqdm
import torch
import pandas as pd
import numpy as np
from raftup import (
_downsample,
_fsgw_utils,
_metrics_two_gpr,
_load_data,
_plot,
_recoverfull_new_new_knn
)
/opt/anaconda3/envs/raftup/lib/python3.10/site-packages/dask/dataframe/__init__.py:31: FutureWarning: The legacy Dask DataFrame implementation is deprecated and will be removed in a future version. Set the configuration option `dataframe.query-planning` to `True` or None to enable the new Dask Dataframe implementation and silence this warning.
warnings.warn(
/opt/anaconda3/envs/raftup/lib/python3.10/site-packages/xarray_schema/__init__.py:1: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import DistributionNotFound, get_distribution
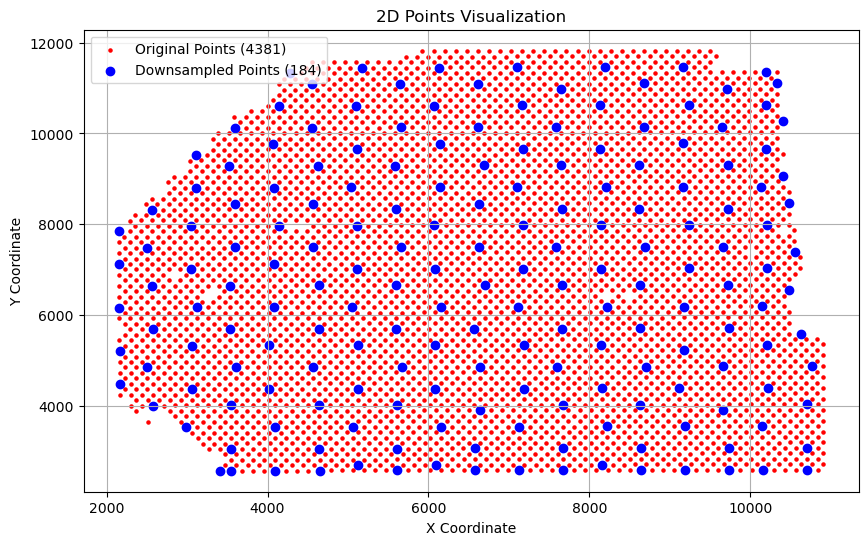
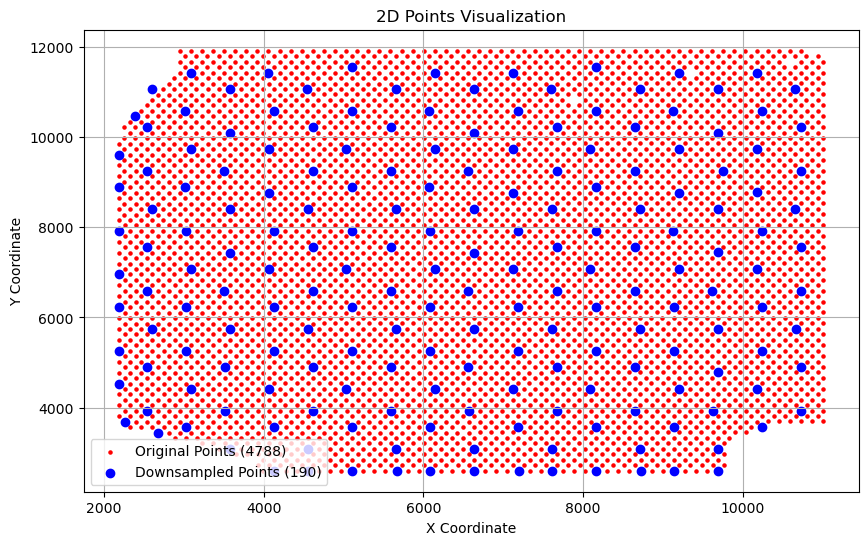
Choose tar_distance so that the two downsampled subslices each contain approximately 190–200 spots. In general, a larger number of retained spots leads to better downsampled alignment performance.
[2]:
section_ids_list = [['151508', '151509']]
pair = "151508_151509"
for section_ids in section_ids_list:
dataset = section_ids[0] + '_' + section_ids[1]
sliceA = _load_data.load_DLPFC(section_id=section_ids[0])
sliceB = _load_data.load_DLPFC(section_id=section_ids[1])
random_state = 23
np.random.seed(random_state)
tar_distance = 1020 # verify
/Users/salovjade/Library/CloudStorage/Dropbox/raftup_repo/src/raftup/_load_data.py:12: FutureWarning: Use `squidpy.read.visium` instead.
ad = sc.read_visium(path=os.path.join(root_dir, section_id), count_file=section_id+'_filtered_feature_bc_matrix.h5')
/opt/anaconda3/envs/raftup/lib/python3.10/site-packages/anndata/_core/anndata.py:1832: UserWarning: Variable names are not unique. To make them unique, call `.var_names_make_unique`.
utils.warn_names_duplicates("var")
/Users/salovjade/Library/CloudStorage/Dropbox/raftup_repo/src/raftup/_load_data.py:12: FutureWarning: Use `squidpy.read.visium` instead.
ad = sc.read_visium(path=os.path.join(root_dir, section_id), count_file=section_id+'_filtered_feature_bc_matrix.h5')
/opt/anaconda3/envs/raftup/lib/python3.10/site-packages/anndata/_core/anndata.py:1832: UserWarning: Variable names are not unique. To make them unique, call `.var_names_make_unique`.
utils.warn_names_duplicates("var")
[3]:
downsampled_sliceA,indices_dsa = _downsample.downsample_slice(sliceA, tar_distance)
_downsample.visualize_downsampled_points(sliceA, downsampled_sliceA)
[4]:
downsampled_sliceB,indices_dsb = _downsample.downsample_slice(sliceB, tar_distance)
_downsample.visualize_downsampled_points(sliceB, downsampled_sliceB)
[5]:
PT_PATH = f"./results/gene_cost_matrix/{pair}_somde_cost_matrix.pt"
CSV_PATH = (f"./results/align_data/{pair}_cost_matrix.csv"
)
C = torch.load(PT_PATH, map_location="cpu")
df = pd.DataFrame(C.numpy())
df.to_csv(CSV_PATH, index=False, header=False)
M = _fsgw_utils.extract_feature_matrix(CSV_PATH, indices_dsa, indices_dsb)
After rescaling: min = 0.03457424913499871, max = 1.0.
[6]:
D_A_test = distance.cdist(downsampled_sliceA.obsm['spatial'], downsampled_sliceA.obsm['spatial'])
D_B_test = distance.cdist(downsampled_sliceB.obsm['spatial'], downsampled_sliceB.obsm['spatial'])
testA = D_A_test[D_A_test>0]
testB = D_B_test[D_B_test>0]
print(np.min(testA), np.min(testB))
137.00364958642524 279.0788419067271
For DLFPC data, 150 \mu `m physical distance = 206 unit distance. In general, for non-adjacent (physical distance of slices great than 200 :nbsphinx-math:mu or unknown distance), gene cutoff = 0.2 and spatial cutoff = 150 :nbsphinx-math:mu `m is a good combo.
[7]:
cutoff_GW_standard = int(np.max([np.min(testA), np.min(testB)]))
cutoff_GW_list = {206}
cutoff_CC_list = {0.2}
SAVE_DIR = Path("./results/align_data")
SAVE_DIR.mkdir(parents=True, exist_ok=True)
test_label_sub = np.concatenate((np.array(downsampled_sliceA.obs['original_clusters']),np.array(downsampled_sliceB.obs['original_clusters'])),axis=0)
XA_sub = downsampled_sliceA.obsm['spatial']
XB_sub = downsampled_sliceB.obsm['spatial']
for cutoff_GW in tqdm(cutoff_GW_list, desc="Running different GW cutoffs for downsampled {pair}"):
for cutoff_CC in cutoff_CC_list:
print(f"\nRunning GW cutoff = {cutoff_GW}, CC cutoff = {cutoff_CC}")
# Run FSGW
P = _fsgw_utils.fsgw_mvc_exp(
D_A_test,
D_B_test,
M,
gw_cutoff=cutoff_GW,
w_cutoff=cutoff_CC,
)
print("P.sum():", P.sum())
save_path = (
SAVE_DIR
/ f"ds_matching_{pair}_{cutoff_GW}_{cutoff_CC}.npy"
)
np.save(save_path, P)
print(f"Saved to: {save_path}")
Running different GW cutoffs for downsampled {pair}: 0%| | 0/1 [00:00<?, ?it/s]
Running GW cutoff = 206, CC cutoff = 0.2
Finding MVC for gw=206, w=0.2: 100%|██████████| 36283995/36283995 [00:52<00:00, 691296.69it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 4074.16it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 4281.08it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 3549.20it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 3771.64it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 4328.06it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 4629.61it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 4817.26it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 3798.63it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 3642.89it/s]
sOT Iterations: 100%|██████████| 10000/10000 [00:02<00:00, 3799.20it/s]
Running different GW cutoffs for downsampled {pair}: 100%|██████████| 1/1 [03:48<00:00, 228.40s/it]
P.sum(): 0.4473684210526131
Saved to: results/align_data/ds_matching_151508_151509_206_0.2_updated_0122.npy